Die Verwandtschaft der Proteine
Zum ersten Mal das Proteom von 100 Organismen aus allen Domänen des Lebens entschlüsselt
Proteine steuern als eines der wichtigsten Biomoleküle das Leben - als Enzyme, Rezeptoren, Signal- oder Strukturmoleküle. Forscher am Max-Planck-Institut für Biochemie haben zum ersten Mal die Proteome von 100 verschiedenen Organismen entschlüsselt. Die ausgewählten Organismen stammen aus allen drei Domänen des Lebens: der Bakterien, der Archaeen oder der Eukaryoten. Mithilfe der Massenspektrometrie wurden 340.000 verschiedene Proteine gemessen. Verwandte, in der Evolution erhaltene Proteine können nun erstmals mengenmäßig miteinander verglichen werden.
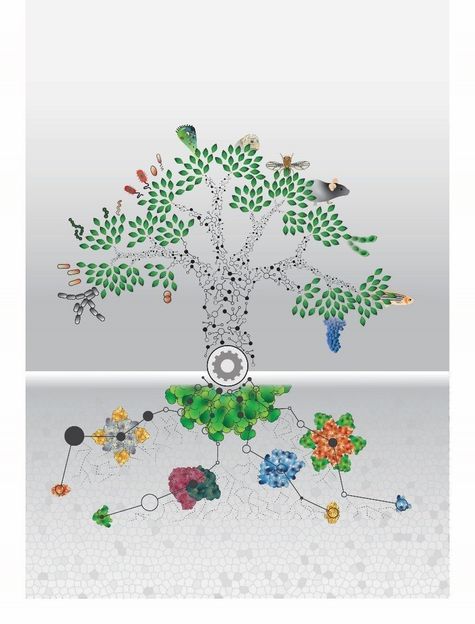
Alle Lebewesen stehen evolutionär in einem Zusammenhang. Die Analyse der Proteome von 100 verschiedenen Organismen aus allen Lebensdomänen liefert eine Vielzahl von neuen molekularen Informationen.
© Johannes B. Müller © MPI of Biochemistry
Was haben die Hausmaus Mus musculus, der in thermalen Quellen lebende Organismus Haloferax mediterranei und das Darmbakterium Escherischia coli gemeinsam? Nichts sollte man meinen, denn diese drei Lebewesen sind in ihrer evolutionären Abstammung weit voneinander entfernt. Sie gehören jeweils zu einer der drei unterschiedlichen Domänen, die höchste Klassifizierungskategorie der Lebewesen: der Eukaryoten, der Archaeen oder der Bakterien. Alle drei Organismen nutzen bestimmte, ähnliche Biomoleküle, Proteine, die für ihr Überleben wichtig sind.
Um neue Gemeinsamkeiten und Unterschiede der Organismen zu entdecken, haben Forscher vom Max-Planck-Institut für Biochemie, in Zusammenarbeit mit Forschungseinrichtungen aus München und Kopenhagen, neben diesen drei Organismen, das Proteom von insgesamt 100 Organismen aus allen Domänen des Lebens analysiert. Das Proteom ist die Gesamtheit der Proteine einer Zelle oder eines Lebewesens.
Johannes Müller, einer der beiden Erstautoren der Studie, erklärt: „Die evolutionäre Verwandtschaft wird heutzutage anhand der Ähnlichkeit von bestimmten Genabschnitten analysiert. Gene, sind die Bauanleitung für Proteine. Mit der aktuellen Studie haben wir die verschieden Genprodukte, die Proteine angeschaut. Wir können jetzt herausfinden, ob die einzelnen Organismen nicht nur die Bauanleitung der Proteine in sich tragen, sondern diese auch herstellen.“
Aufwändige Proteinanalyse
Matthias Mann, Leiter der Abteilung „Proteomics und Signaltransduktion“, und sein Team sind Experten für die Proteinanalyse. Mithilfe des Hochdurchsatzverfahrens der Massenspektrometrie können bekannte und unbekannte Proteine identifiziert und in ihrer Menge bestimmt werden. Bioinformatische Verfahren erlauben anschließend die Analyse und die Integration von zusätzlichen Informationen aus wissenschaftlichen Datenbanken.
Durch die Quantifizierung der gemessenen Proteine können Homologe, also evolutionäre verwandte Proteine, zwischen den Organismen verglichen werden. Die Daten erlauben es den Forschern grundlegende Fragen zu beantworten, wie beispielsweise: Worin investieren Lebewesen über alle Domänen hinweg am meisten ihrer Ressourcen? Verwandte, in der Evolution konservierte Proteine können nun erstmals mengenmäßig miteinander verglichen werden.
In keiner vorherigen Proteomics-Studie wurden so viele Proteine detektiert und quantifiziert. Es wurden zwei Millionen individuelle Peptide von insgesamt 340.000 Proteinen gemessen. Peptide sind Teilstücke von Proteinen. Die detektierten Proteinabschnitte wurden mithilfe von Datenbanken bekannter und vorhergesagter Genprodukte Proteinen zugeordnet und mit anderen bekannten Datenbankinformationen verknüpft. Dies führte zu einer unglaublichen Datensammlung von acht Millionen Datenpunkten mit 53 Millionen Verbindungen.
Neue Erkenntnisse
„Wir konnten die Existenz von angenommenen, aber nie bestätigten Proteinen beweisen. Viele Proteine waren bisher nur als Vorhersage, anhand der bekannten Gensequenz, geläufig. 93 Prozent der von uns gemessenen Proteine waren bislang noch nicht experimentell bestätigt“, erklärt Johannes Müller.
Es war schon bekannt, dass es Gene gibt, die über alle Domänen hinweg sehr ähnlich sind. Dazu gehören die Gene von Proteinfaltungshelfern, der Proteinherstellungsmaschinerie oder des Energiestoffwechsels. Mithilfe der Studie konnten die Forscher jetzt zeigen, dass die dazugehörige Proteine in allen Organismen in hoher Konzentration hergestellt werden. Johannes Müller erläutert: „Es ist nachvollziehbar, dass beispielsweise die Proteinfaltungshelfer für alle Organismen überlebenswichtig sind und deshalb über alle Domänen hinweg vorkommen. Damit Proteine ihre spezifische Funktion ausführen können, müssen diese in eine sehr individuelle dreidimensionale Form gefaltet werden. Dabei helfen die Faltungshelfer. Ein Rezeptorprotein kann, zum Beispiel, nur dann funktionieren, wenn er die richtige Form hat, um ein Signalmolekül zu binden.“
Aus dem jetzt zur Verfügung gestellten Rohdatensatz kann die Forschungsgemeinschaft in Zukunft noch viele weitere Erkenntnisse gewinnen. Matthias Mann fasst zusammen: „Wir stellen der Öffentlichkeit eine bisher nicht dagewesene Ressource an proteomischen Daten zur Verfügung um das biologische Wissen zu vermehren. Bildlich gesprochen: Mit den Proteomdaten der 100 verschiedenen Organismen haben wir neues molekulares Detailwissen generiert. Wie auf 100 Landkarten können wir nun in viele Teilbereiche hineinzoomen und neue Zusammenhänge entdecken und die Daten miteinander vergleichen. Sowohl für jeden Proteinforscher, der seine zu untersuchenden Proteine in anderen Organismen überprüfen will, als auch für Bioinformatiker, die von unseren Rohdaten bis zu unseren systembiologischen Erkenntnissen profitieren, sind diese Ergebnisse eine Ressource von unschätzbarem Wert. Unter der großen Menge an noch nicht charakterisierten Proteinen befinden sich bestimmt noch viele, die besonders wichtig für das Leben sind und somit für die Medizin von Interesse sein könnten und für die Biotechnologie um die ‚Grüne Chemie‘ zu vorran zu treiben.“
Originalveröffentlichung
Weitere News aus dem Ressort Wissenschaft




















Diese Produkte könnten Sie interessieren

Kjel- / Dist Line von Büchi
Kjel- und Dist Line - Wasserdampfdestillation und Kjeldahl-Anwendungen
Maximale Genauigkeit und Leistung für Wasserdampfdestillation und Kjeldahl-Anwendungen

AZURA Purifier + LH 2.1 von KNAUER
Präparative Flüssigkeitschromatografie - Neue Plattform für mehr Durchsatz
Damit sparen Sie Zeit und verbessern die Reproduzierbarkeit beim Aufreinigen

Meistgelesene News





Weitere News von unseren anderen Portalen






























Verwandte Inhalte finden Sie in den Themenwelten
Themenwelt Massenspektrometrie
Die Massenspektrometrie ermöglicht es uns, Moleküle aufzuspüren, zu identifizieren und ihre Struktur zu enthüllen. Ob in der Chemie, Biochemie oder Forensik – Massenspektrometrie eröffnet uns ungeahnte Einblicke in die Zusammensetzung unserer Welt. Tauchen Sie ein in die faszinierende Welt der Massenspektrometrie!
Themenwelt Massenspektrometrie
Die Massenspektrometrie ermöglicht es uns, Moleküle aufzuspüren, zu identifizieren und ihre Struktur zu enthüllen. Ob in der Chemie, Biochemie oder Forensik – Massenspektrometrie eröffnet uns ungeahnte Einblicke in die Zusammensetzung unserer Welt. Tauchen Sie ein in die faszinierende Welt der Massenspektrometrie!
Themenwelt Proteinanalytik
Die Proteinanalytik ermöglicht einen tiefen Einblick in diese komplexen Makromoleküle, ihre Struktur, Funktion und Wechselwirkungen. Sie ist unerlässlich für die Entdeckung und Entwicklung von Biopharmazeutika, das Verständnis von Krankheitsmechanismen und die Identifizierung von therapeutischen Zielen. Durch Techniken wie Massenspektrometrie, Western Blot und Immunoassays können Forscher Proteine auf molekularer Ebene charakterisieren, ihre Konzentration bestimmen und mögliche Modifikationen identifizieren.

Themenwelt Proteinanalytik
Die Proteinanalytik ermöglicht einen tiefen Einblick in diese komplexen Makromoleküle, ihre Struktur, Funktion und Wechselwirkungen. Sie ist unerlässlich für die Entdeckung und Entwicklung von Biopharmazeutika, das Verständnis von Krankheitsmechanismen und die Identifizierung von therapeutischen Zielen. Durch Techniken wie Massenspektrometrie, Western Blot und Immunoassays können Forscher Proteine auf molekularer Ebene charakterisieren, ihre Konzentration bestimmen und mögliche Modifikationen identifizieren.